2008年02月29日
Visual Studio 2008のマルチスレッドデバッグ機能
| 開発環境 | Visual C++ 2008(Standard Edition以上) |
本日はVisual Studio 2008のマルチスレッドデバッグ機能を紹介します。
従来のVisual Studioからあった機能ですが、ほんのちょっとだけ進化しているようです。
Visual Studio 2008のマルチスレッドデバッグ機能
まずは従来からある機能を紹介します。
Visual Studio 2008でマルチスレッドアプリケーションをデバッグ実行すると、
以下のようなスレッドウィンドウを見ることができます。
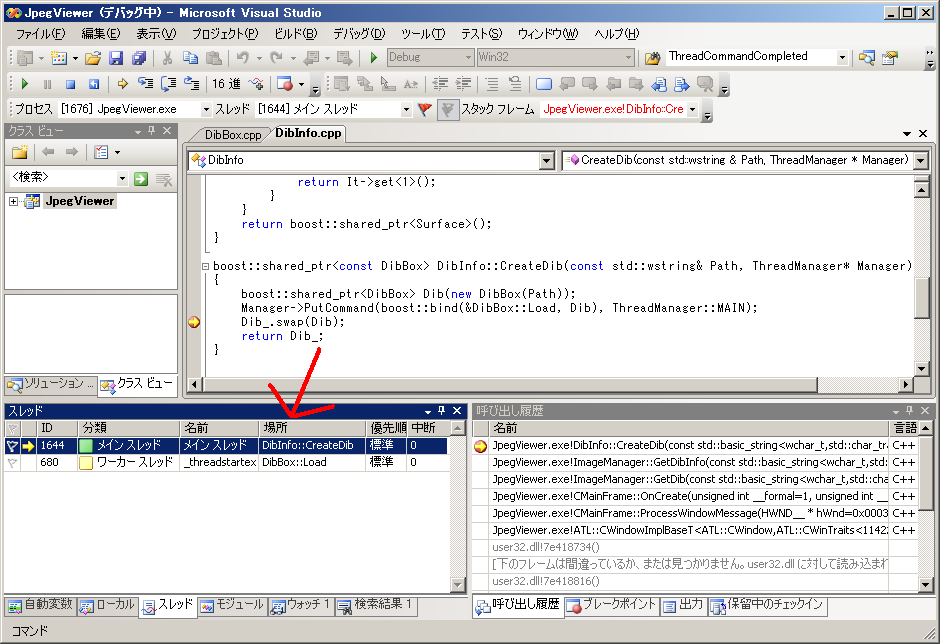
大体見た目通りの機能です。
それぞれのスレッドのIDや名前、実行中の場所を表示してくれます。
この場合は、メインスレッドがDibInfo::CreateDibを実行中で、ワーカースレッドがDibBox::Loadを実行中であることが分かります
(DibInfoがなんであるかとかそういうのは気にしないで下さい)。
スレッドウィンドウのワーカースレッドをクリックすると、以下のようになります。
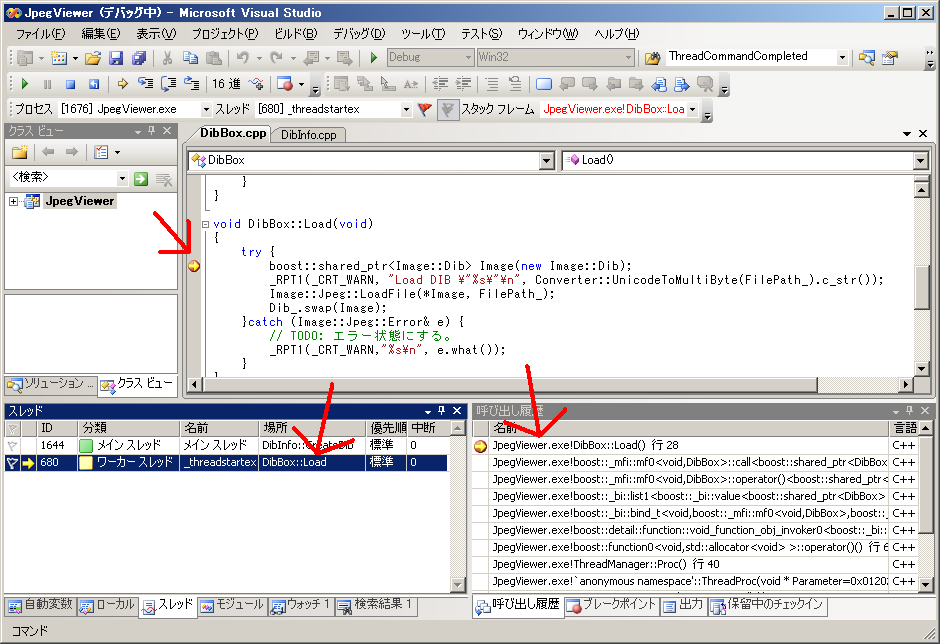
ワーカースレッドの実行中の場所のソースコードが表示され、呼び出し履歴もワーカースレッドのものになります。
スレッドウィンドウを右クリックすると、以下のようなメニューが表示されます。
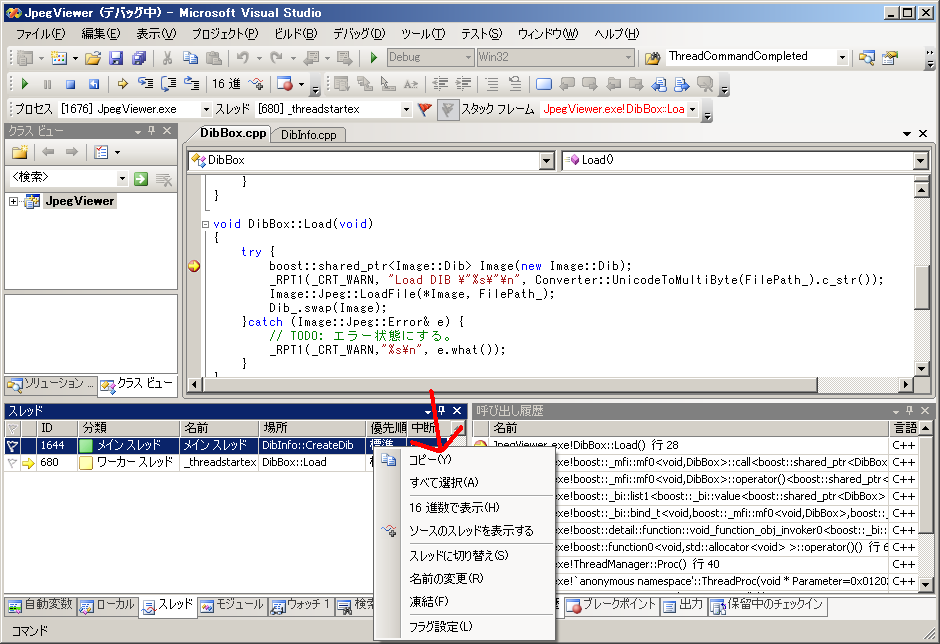
スレッドの凍結(=SUSPEND)やフラグ設定ができます。
フラグ設定はVisual Studio 2008の新機能です。フラグを設定すると、設定されていないスレッドと簡単に区別できるようになります。
スレッドがたくさんあり、注目したいスレッドを絞り込みたいときに便利そうです。上記の例のようにスレッドが2つのときはなんの役にも立ちませんが。
「16進数で表示」を選ぶとスレッドIDが16進数で表示されます。これもたぶんVisual Studio 2008の新機能です。
新機能というにはしょぼいですが、スレッドIDを16進数でデバッグ出力するようなコードと相性が良いです。
Visual Studio 2008のマルチスレッドデバッグ機能はこれで全てのようです。
特定のスレッドだけのステップ実行機能は欲しいと思ったのですが、無いようです(なんでやねん)。
他のスレッドを全て凍結させてからステップ実行すれば実現できますが、面倒です。
以上で紹介はお終いです。
今までより進化したのかどうか微妙なところです。
まだ使い込んでいないので安定性は分かりません。
Visual Studio 6.0やVisual Studio.NET 2003では、マルチスレッドアプリデバッグ中に開発環境が落ちる(反応しなくなる)ことが
良くありました。改善されているのを期待したいところです。
2008年02月27日
Unicodeアプリケーションでファイルオープン
| 開発環境 | Visual C++ 2008 |
Visual Studio 2008を買ってからほぼ毎日ちょっとずつ触っていますが、GUIが今まで使っていたVisual Studio.NET 2003とあんまり変わらないので慣れるのは早そうです。
まだboostが公式に2008に対応していないあたりがちょっと辛いですが。
Unicodeアプリケーションでファイルオープン
C++では、昔は半角文字は1バイト、全角文字は2バイトと可変長になっており、文字列処理が大変面倒でした。
JavaやC#では、半角文字も全角文字も1文字2バイト固定になっていて、大変羨ましく感じたものでした。
そこで、C++でも文字を扱うときはwchar_tを使い、1文字を固定長にしようとしてみたことがあります。
文字列はstd::wstringを使えば問題なかったのですが、標準ライブラリを使ったファイルI/Oに問題がありました。
Visual Studio.NET 2003のstd::fstreamのopenメンバは、
open(const char *_Filename, (略)
しかありませんでした。wchar_tベースのファイル名をstd::fstreamに渡すことができなかったのです。
そこで仕方がなく、WideCharToMultiByteを使ってcharベースの文字列に変換したり、別のライブラリを使ったりしていますた。
これが、Visual Studio 2008では解決されています(Visual Studio 2005の時点で既に解決されていたみたいです)。
std::fstreamに
open(const wchar_t *_Filename, (略)
というメンバが追加されました。これでファイル名をwchar_tベースで管理できます。ありがたいことです。
ようやくUnicodeアプリケーションのファイルI/Oに標準ライブラリを使えるようになりました。
2008年02月26日
Visual Studio 2008のインテリセンス
| 開発環境 | Visual C++ 2008 |
| ライブラリ | boost 1.34.1 |
Visual Studio 2008のインテリセンスは、Visual Studio.NET 2003に比べて良くなっています。(Visual Studio 2005は持ってないので比較できません)
特にboostを使ったコードが書きやすくなっています。例を数点紹介します。
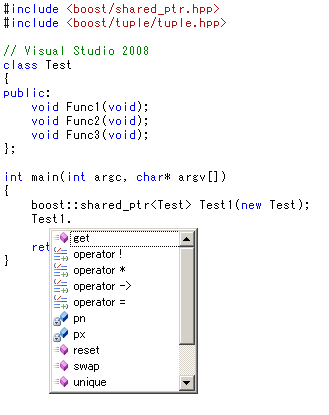
boost::shared_ptr
boost::shared_ptr越しでもちゃんとメンバ一覧が表示されます。
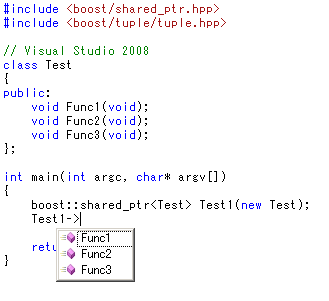
boost::shared_ptr自身のメンバもばっちり
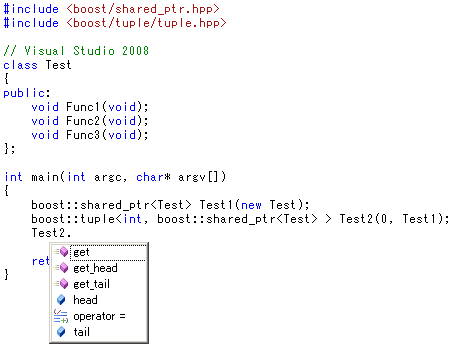
boost::tuple
boost::tupleも問題ありません。
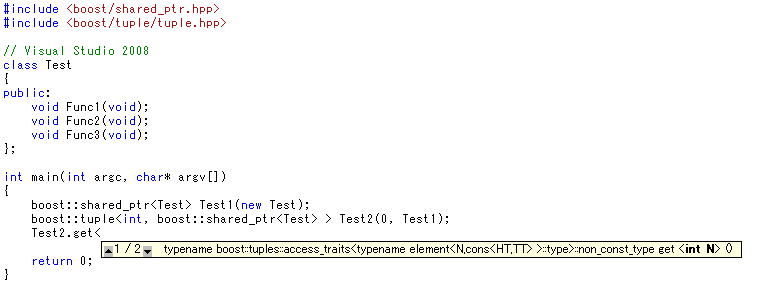
メンバ関数テンプレートなので、<>を入れろということまで教えてくれます。
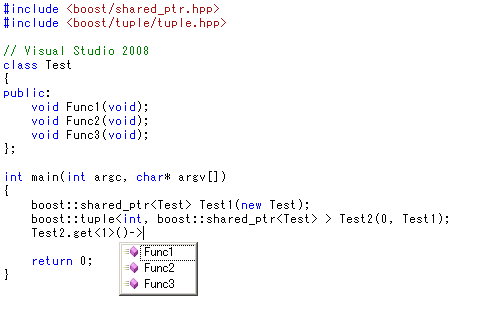
boost::tupleとboost::shared_ptrが組み合わさっていても問題なし。
透明化
こんなおまけ機能もあります。候補ウィンドウ表示中に、Ctrlを押すとウィンドウが半透明になります。というよりほとんど見えなくなります。
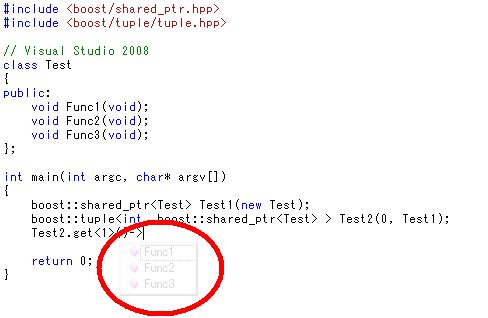
これはVisual Studio 2008の新機能らしいです。
コードが混み合っている時は便利かもしれません。
補足
なお、Visual Studio.NET 2003では、上記のインテリセンスは全てこのメッセージで拒否されました。
![]()
2008年02月18日
libjpeg高速化改造版の使い方(Visual Studio 2008)
ソフトウェア工房αさんがリリースしているlibjpeg高速化改造版をVisual Studio 2008で使う方法を調べましたので、まとめておきます。
(正式名称はIndependent JPEG Group's JPEG software release 6b with x86 SIMD extension for IJG JPEG library version 1.02)
(Visual C++.NET 2003の場合はこちら)
必要なもの
- Visual Studio 2008(Visual C++ 9.0)
- NASM(nasm-2.02rc2-win32.zip)。SourceForge.net The Netwide Assemblerからダウンロード可能。
- libjpeg高速化改造版ソースコード(jpegsrc-6b-x86simd-1.02.tar.gz)。libjpegの高速化改造版のページからダウンロード可能
- プロジェクトファイル一式。ダウンロードはこちら
手順
- NASMを適当なフォルダに展開します。
- ツール→オプション→プロジェクトおよびソリューション→VC++ ディレクトリ→ディレクトリを表示するプロジェクト→実行可能ファイル にNASMを展開したフォルダのパスを追加します。
- プロジェクトファイル一式をjpeglib.hと同じ場所に置きます。
- libjpegx.slnを開いて全構成をビルドします。lib-vc90フォルダ以下にC++ランタイムに合わせた4種類のlibファイルが作成されます。
libjpeg高速化改造版の機能は、jpeglib.hを#includeすると使えるようになります。
2008年02月17日
libjpegの使い方(Visual Studio 2008)
IJGが配布しているIJG JPEG library(libjpeg、jpeglib、jpeg-6bと呼ばれることもあるようです)をVisual Studio 2008で使う方法を調べましたので、まとめておきます。
(Visual C++.NET 2003の場合はこちら)
必要なもの
- Visual Studio 2008(Visual C++ 9.0)
- IJG JPEG library ソースコード(jpegsrc.v6b.tar.gz)。IJGからダウンロード可能
- プロジェクトファイル(libjpeg.vcproj)。ダウンロードはこちら
手順
- libjpeg.vcprojをjpeglib.hと同じ場所に置きます。
- libjpeg.vcprojを開いて全構成をビルドします。lib-vc90フォルダ以下にC++ランタイム毎の4種類のlibファイルが作成されます。
Visual C++.NET 2003はC++ランタイムが6種類あったのですが、2008ではシングルスレッド用のランタイムがなくなり、4種類になったようです。
libjpegの機能は、jpeglib.hを#includeすると使えるようになります。
このとき、標準的なヘッダ(windows.hなど)と干渉を起こすことがありますが、以下のように書くと回避できます。
#define XMD_H
#undef FAR
extern "C" {
#include <jpeglib.h>
}
以上です。
2008年02月16日
Visual Studio 2008を買ってみました。
「Visual Studio 2008 Professional Edition アップグレード」なるものを買ってみました。

私の場合はVisual Studio.NET 2003からのアップグレードになります。
私が使うのはC++です。Visual Studio.NET 2003のC++開発環境は標準への準拠度が高く、boostライブラリもちゃんと使えて良い開発環境でした。 C++しか使わないのであれば、当面Visual Studio.NET 2003で十分だと思っていたのですが、 VistaでVisual Studio.NET 2003がサポートされない という悲しい出来事があり、やむなくアップグレードすることにしました。
インストールメディアですが、DVD1枚にまとまっていました。
インストールは相変わらず数時間かかりますが、昔のようにCD入れ替えの手間が無く、楽でした。
インストール後にService Releaseのチェックをしようとすると、
IEでしか見れないページをデフォルトブラウザ(私の場合はFirefox)で開くのはちょっと困りました。
IEでしか見れないページならばちゃんとIEを使って欲しいところです。
価格は、アップグレード版は61,236円、アップグレードじゃない方は120,960円。6万円も違いがあります。
アップグレード版の適用範囲は異常に広く、
6万円以内の商品もたくさんあります。
Officeの方もこんな感じでした。
Microsoftのアップグレード版の価格戦略は良く分かりません。
ちなみに私はVisual C++ 9.0 Express EditionしかインストールしていないノートPCにアップグレード版をインストールしてみたのですが、
CDを要求されることもなくすんなりインストールできてしまいました。うーむ一体これは・・・?
2008年02月12日
Shift_JISとUnicodeの変換用関数
- 環境
- Visual C++.NET 2003
以前書いたコードのバージョンアップ版です。
仕様は以前と同じです。若干コードがスマートになっている・・・かもしれません。
Unicodeからマルチバイト文字(Shift_JIS)への変換関数
std::string UnicodeToMultiByte(const std::wstring& Source, UINT CodePage = CP_ACP, DWORD Flags = 0);
std::string UnicodeToMultiByte(const std::wstring& Source, UINT CodePage, DWORD Flags)
{
std::vector<char> Dest(::WideCharToMultiByte(CodePage, Flags, Source.c_str(), static_cast<int>(Source.size()), NULL, 0, NULL, NULL));
return std::string(Dest.begin(),
Dest.begin() + ::WideCharToMultiByte(CodePage, Flags, Source.c_str(), static_cast<int>(Source.size()), &Dest[0], static_cast<int>(Dest.size()), NULL, NULL));
}
マルチバイト文字(Shift_JIS)からUnicodeへの変換関数
std::wstring MultiByteToUnicode(const std::string& Source, UINT CodePage = CP_ACP, DWORD Flags = 0);
std::wstring MultiByteToUnicode(const std::string& Source, UINT CodePage, DWORD Flags)
{
std::vector<wchar_t> Dest(::MultiByteToWideChar(CodePage, Flags, Source.c_str(), static_cast<int>(Source.size()), NULL, 0));
return std::wstring(Dest.begin(),
Dest.begin() + ::MultiByteToWideChar(CodePage, 0, Source.c_str(), static_cast<int>(Source.size()), &Dest[0], static_cast<int>(Dest.size())));
}
ところで、C++標準ライブラリを使ってプログラムするとき、wchar_tをメインに使おうとすると、ファイルが開けなくてこまります。
なんでstd::fstreamはファイル名にconst char *しか指定できないんでしょうね。
おかげでこんな変換関数を使うハメに陥ってしまいます。