2007年09月22日
ファイル読み出しコードの性能評価
C++でファイルの内容をメモリ上に読み出すコードを書いてみたところ、 書き方によって結構性能に差がありました。そこでちょっと性能を調べてみましたのでまとめておきます。
読み出しコード
C++では、メモリ上でのデータ保持方法は色々ありそうですが、
代表的なものということで、std::stringとstd::vector
1つめのコード。Case1とします。
// Case1 using namespace std; string Data(istreambuf_iterator<char>(ifstream(FileName, ios::in | ios::binary)), istreambuf_iterator<char>());一行でも書ける短いコードです。
2つめのコード。Case2とします。
// Case2 using namespace std; vector<char> Data(istreambuf_iterator<char>(ifstream(FileName, ios::in | ios::binary)), istreambuf_iterator<char>());std::vectorを使ったこと以外はCase1と同じです。
3つ目のコード。Case3とします。
// Case3 using namespace std; vector<char> Data; copy(istreambuf_iterator<char>(ifstream(FileName, ios::in | ios::binary)), istreambuf_iterator<char>(), back_inserter(Data));std::back_inserterを使ったC++らしいコードです。
最後のコード。Case4とします。
// Case4 using namespace std; vector<char> Data; std::ifstream Input(FileName, std::ios::in | std::ios::binary); Data.resize(Input.seekg(0, std::ios::end).tellg()); Input.seekg(0, std::ios::beg).read(&Data[0], static_cast<std::streamsize>(Data.size()));C言語に近い古い書き方。 シークしてファイルサイズを求めたら一気に読みだしています。
読み出しファイル
大きなファイルであれば何でも良いと思いましたので、 makedummyというツールを使って作った100MB(104,857,600 Bytes)のファイルを使いました。データはランダムです。
測定環境
測定環境は以下の通りです。
| コンパイラ | Visual C++.NET 2003デフォルトコンパイラ |
| OS | Windows XP Professional SP2 |
| CPU | AMD Athlon 64 3700+ |
| メモリ | 2GB |
| HDD | Seagate ST3300622AS |
| ファイルシステム | NTFS |
| プロジェクト設定 | デフォルトRelease構成 |
測定結果
100MB位だとディスクキャッシュに格納されてしまうみたいなので、OS起動直後のファイルキャッシュに格納される前の読み出し時間を測るようにしました。
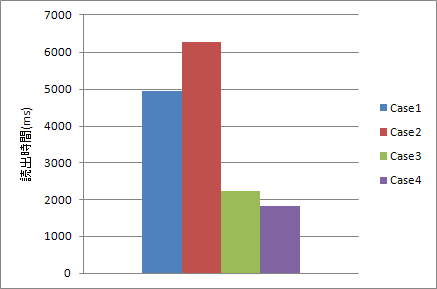
結果は以下の通り。
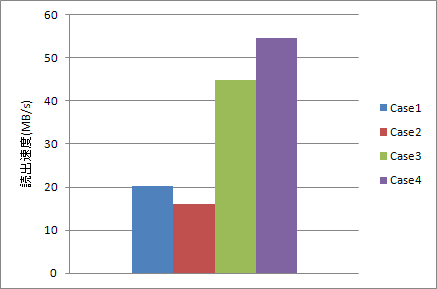
時間を速度に変換してみました。1MB/s=1024×1024Byte/s です。
分かったこと。
- コンストラクタで読み出すCase1やCase2よりも、std::copyとback_inserterで読みだすCase3の方が速いです。
コンストラクタでできることはコンストラクタでやるべきと思っていましたが、そうとも限らないようです。 - それよりもさらにifstream::readで一気に読みだすCase4の方が速いです。なんと一番です。
速度を重視するときはCase4が一番なのかもしれませんね。
2007年09月14日
libjpeg高速化改造版の性能を簡単に評価 その2
「libjpeg高速化改造版の性能を簡単に評価」の続きです。
libjpeg(以下、通常版)とその高速化改造版の性能をもうちょっと比べてみました。
性能測定ポイント
以下のJPEG読み出し~表示までのステップのうち、前回性能を測定したのは、2.でした。
- ファイルから読み出す。
- libjpegで非圧縮画像イメージに展開する。
- WindowsのDIB形式に合うよう、非圧縮画像イメージの色の並びをRed,Green,Blueから、Blue,Green,Redに変更する。
- CreateDIBitmapでDDB形式のビットマップを作成します。
- BitBltでウィンドウペイント用デバイスコンテキストに描画する。
測定結果
画像データと測定環境は前回と同じです。
測定結果は以下の通り。
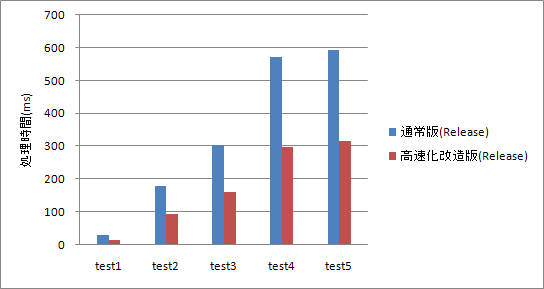
処理時間は半分強ですね。前回の測定結果とあまり変わらない結果になりました。
結局のところ、libjpeg高速化改造版は、通常版に比べて倍ほど速いようです。
4.~5.の処理時間と1.~3.の処理時間の割合はどうなっとるんやというのはもう勘弁して下さい。 libjpeg高速化改造版のお話はこれでおしまいです。
(2007/09/15 追記)
あれこれ追試した結果、上記の1の処理は、ファイルキャッシュからの読み出しのようです。HDDからではありません。
HDDから読み出した場合はまた別の結果になると思われます。
2007年09月13日
libjpeg高速化改造版の性能を簡単に評価
「libjpeg高速化改造版の使い方(Visual C++.NET 2003)」の続きです。 libjpeg(以下、通常版)とその高速化改造版の性能をちょっと測ってみましたので、まとめておきます。
性能測定ポイント
最初に、性能を測ったポイントを説明します。
JPEGファイルを読みだしてから画面に表示するまでのステップを以下に示します。
- ファイルから読み出す。
- libjpegで非圧縮画像イメージに展開する。
- WindowsのDIB形式に合うよう、非圧縮画像イメージの色の並びをRed,Green,Blueから、Blue,Green,Redに変更する。
- CreateDIBitmapでDDB形式のビットマップを作成します。
- BitBltでウィンドウペイント用デバイスコンテキストに描画する。
1.でファイルから読みだしたデータをメモリ上に確保しておいて、 2.ではメモリ上のデータを展開するようにしました。
画像データ
画像データは以下の5つのデータを使うことにしました。私が普段使っている画像データです。
- test1.jpg(65,349 Byte)、デジカメ撮影データを1024x685まで縮小したデータ。
- test2.jpg(1,243,981 Byte)、デジカメ撮影データを2128x1424にトリミングしたデータ。
- test3.jpg(2,434,484 Byte)、デジカメ撮影データを2716x1816にトリミングしたデータ。
- test4.jpg(3,243,436 Byte)、デジカメ撮影データそのまま(3872x2592)。
- test5.jpg(4,234,112 Byte)、デジカメ撮影データそのまま(3872x2592)。ファイルサイズ大きめのものをチョイス。
測定環境
測定環境は以下の通りです。
| コンパイラ | Visual C++.NET 2003デフォルトコンパイラ |
| OS | Windows XP Professional SP2 |
| CPU | AMD Athlon 64 3700+ |
| メモリ | 2GB |
| プロジェクト設定 | デフォルトRelease構成 |
測定結果
測定結果は以下の通り。
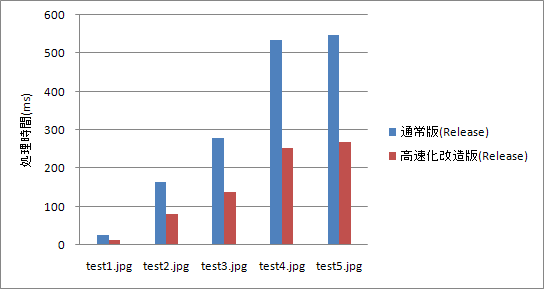
処理時間が半分になりました。2倍速です。
劇的というほど速くはなりませんが、地味に効きそうな数字です。
最近はデジカメの高画素化に伴い、巨大なJPEGファイルが増えているので、アプリケーションによっては有効だと思います。
おまけ
ついでにRelease構成とDebug構成も比べて見てみました。
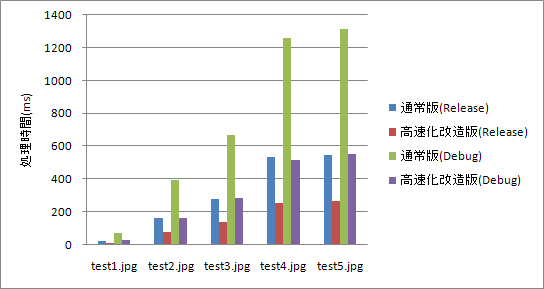
通常版を比べてみると、Release版の処理時間はDebug版の4割ほどになってます。2.5倍速です。
コンパイラも結構頑張ってますね。
2007年09月12日
libjpeg高速化改造版の使い方(Visual C++.NET 2003)
「libjpegの使い方(Visual C++.NET 2003)」の続きです。
ソフトウェア工房αさんがリリースしているlibjpeg高速化改造版の使い方を調べましたので、まとめておきます。
(正式名称はIndependent JPEG Group's JPEG software release 6b with x86 SIMD extension for IJG JPEG library version 1.02)
必要なもの
- Visual C++ 2003.NET
- NASM(nasm-0.98.39-win32)。SourceForge.netからダウンロード可能。
- libjpeg高速化改造版ソースコード(jpegsrc-6b-x86simd-1.02.tar.gz)。libjpegの高速化改造版のページからダウンロード可能
- プロジェクトファイル一式(20070912_libjpegx.lzh)
手順
- NASMを適当なフォルダに展開します。
- ツール→オプション→プロジェクト→VC++ ディレクトリ→ディレクトリを表示するプロジェクト→実行可能ファイル にNASMを展開したフォルダのパスを追加します。
- プロジェクトファイル一式をjpeglib.hと同じ場所に置きます。
- vc6proj/jconfig.hをひとつ上のフォルダ(jpeglib.hなどと同じフォルダ)にコピーします。
- libjpegx.slnを開いて全構成をビルドします。libフォルダ以下にC++ランタイムに合わせた6種類のlibファイルが作成されます。
libjpeg高速化改造版の機能は、jpeglib.hを#includeすると使えるようになります。
libjpegと違い、標準的なヘッダ(windows.hなど)と干渉を起こすことは無いようですので、#includeだけで良さそうです。
「libjpeg高速化改造版の性能を簡単に評価」に続きます。
2007年09月11日
libjpegの使い方(Visual C++.NET 2003)
Visual C++.NET 2003でIJGが配布しているIJG JPEG library(libjpeg、jpeglib、jpeg-6bと呼ばれることもあるようです)を使う方法を調べましたので、まとめておきます。
必要なもの
- Visual C++.NET 2003
- IJG JPEG library ソースコード(jpegsrc.v6b.tar.gz)。IJGからダウンロード可能
- プロジェクトファイル(20070911_libjpeg.lzh)。
手順
- libjpeg.vcprojをjpeglib.hと同じ場所に置きます。
- jconfig.vcをjconfig.hにcopyします。
- libjpeg.vcprojを開いて全構成をビルドします。libフォルダ以下にC++ランタイムに合わせた6種類のlibファイルが作成されます。
libjpegの機能は、jpeglib.hを#includeすると使えるようになります。
このとき、標準的なヘッダ(windows.hなど)と干渉を起こすことがありますが、以下のように書くと回避できます。
#define XMD_H
#undef FAR
extern "C" {
#include <jpeglib.h>
}
以上です。 libjpegの使い方は適当に検索すれば見つかります。 快適なjpegライフをお楽しみ下さい。
2007年09月10日
Microsoft Officeの正しい(?)買い方
私は今まで家ではOpen Officeを使っていたのですが、
会社で使用しているMicrosoft Officeと使い勝手が違く、いまいち感が漂っていました。
そこで会社に合わせてMicrosoft Officeを購入することにしました。
PowerPointを使いたいのでスイートはOffice Standard 2007を選びました。 私は古いOfficeを持っていないので、当然標準版ということになりそうですが、Microsoftが奇妙な価格をつけているので、別の路を選ぶことにしました。
Office Standard 2007は、標準版が53000円位で、アップグレード版が28000円くらいと、25000円位違います。結構な違いです。
これに対し、アップグレード版の対象商品はたくさんあります。
WordやExcelなどの単体商品からでもアップグレードできます。
ということは、こうした商品の中から25000円以下のものを合わせて買えば、アップグレード版の方が安くなるのです。
電器屋さんの店員と相談しても問題なさそうだという話になったので、試しに買ってみることにしました。
25000円より安い単体製品はいくつかありますが、せっかくだから使うかもしれないものにしておこうということで、OneNoteを選びました。
OneNote 標準版が12000円位なので、OneNote 標準版と、Office Standard アップグレード版で40000円です。Office Standared 標準版(53000円)より10000円以上お得な上、OneNoteまで手に入るわけです。
早速インストールして使ってみましたが、問題ありませんでした。WordもPowerPointもライセンス認証に成功して普通に使えます。もちろんOneNoteも。
OneNoteを先にインストールしなければならないので、若干インストールの手間が増えることにはなりますが、
インストールのときだけなので普段は関係ありません。
問題がなくて拍子抜けでした。
こんな不思議な価格にした狙いは、OneNoteの普及なのですかね。 確かに必要がなさそうなのに買ってしまった上、ちょっとだけ使ってみてしまいました。 効果はあるのかもしれません。
2007年09月07日
boost::arrayの初期化
Boost C++Librariesプログラミング 第2版を読んで気が付いたのですが、
boost::arrayクラスのオブジェクトは不思議な方法で初期化できます。
こんな方法です。
boost::array<int, 5> a = {0, 1, 2, 3, 4};
どんなコンストラクタを書けばこのように初期化できるようになるのかさっぱり分からなかったので、調べてみました。
結論。
boost::arrayにコンストラクタはありませんでした。デストラクタもありません。
仮想関数も無く、全てのメンバがpublicです。
どうやら、POD(Plain Old Data)型になる条件が満たされているようです。
つまりboost::array<int, 5>は、C言語互換の構造体なのです。
C言語時代、構造体は次のような方法で初期化できました。
struct foo {
int elem[5];
};
struct foo a = {0, 1, 2, 3, 4};
C++でも、C言語互換の構造体は同じ方法で初期化できます。 だから、boost::array<int, 5>の初期化は上記のようにできたのです。
古きC言語の構造体規則と新しきC++のテンプレート規則の見事な融合を見た気がしました。
(2007/09/13追記)
正確には、「集成体型」であれば上記のように初期化できるようです。POD型よりも若干条件が緩いようです)
2007年09月06日
Boost C++Librariesプログラミング 第2版
Boost C++Librariesプログラミング 第2版
という本を読みましたので感想を書きます。
Let's boostの中の人によるboostライブラリの解説本です。
boostというのが何か、についてはGoogleで検索して下さい。
本書が扱っているboostのバージョンは現時点で最新の1.34です。
さらに一部1.35に追加される予定の非同期I/Oの説明が含まれています。
boostというのはC++のテンプレートを使った強力なライブラリなのですが、結構難解なので、使いこなすのは結構難しいです。
特に、使い方を間違えたとき、正しい使い方に辿りつくのが難しいのです。コンパイラが吐き出すエラーメッセージは意味不明ですし、
デバッガで動作を追ってもあちこちにジャンプするので、何をしているのか良く分かりません。
そこで、私は便利そうで簡単なライブラリ(boost::shared_ptrなど)を使いながら理解を深めていこうとしています。
本書は、boostとこういう付き合い方をしている方にお薦めの一冊です。
一気に理解を深めるほど効果があるものではありませんが、今まで使っていたライブラリへの理解がちょっと深まったり、
知らなかった便利で簡単なライブラリが見つかったりします。
例えば、私にとってはこんなありがたいことがありました。
- 正規表現はライブラリをリンクしないと使えないものだと思っていましたが、 ヘッダファイルのインクルードだけで使える正規表現ライブラリboost::xpressiveの存在を知りました。 お手軽に正規表現が使えそうです。
- boost::algorithm::to_upperやto_lowerで大文字/小文字変換ができることを知りました。 ポータブルな大文字/小文字変換ってあんまり簡単じゃないのでこうして提供してくれるのは助かります。
- TCP/IPを取り扱うライブラリ(boost::asio::ip)の存在を知りました。但し使えるのはboost 1.35からのようですが。 SSLを扱うライブラリ(boost::asio::ssl)まであるなんてびっくりです。ついにboostにネットワークが入りました。
- zlibで圧縮/展開するストリームライブラリ(boost::iostreams::zlib_compressor/zlib_decompressor)の存在を知りました。 これからはzlibを自前で呼ばなくても良いようです。
- オブジェクトの直列化を行うライブラリ(boost::archive)の存在を知りました。 リンク構造まで気合を入れて直列化してくれるみたいです。 xml_oarchiveやxml_iarchiveクラスを使うとXML形式でオブジェクトを保存できます。ついにboostにXMLが!! でもシリアライズをするだけのXMLライブラリなのかな?ポータブルな汎用XMLライブラリが欲しい・・・
- 乱数生成エンジンはたくさんあってどれが良いのか迷うことがありましたが、 メルセンヌツイスターを使ったboost::random::mt19937が周期が長く分布が均等で高速なのでお薦めされていることを知りました。 こうしてお薦めして貰えると助かります。
- 関数オブジェクトは、boost::functionを使って保存できることを知りました。 関数オブジェクトを作り出すboost::bindは使っていましたが、保存できることは知りませんでした。Commandパターンを実装するときに使えそうです。
- boostには単体テスト用フレームワーク(boost::unit_test_framework)があることを知りました。 cpptestとどちらを使うかは悩みどころです。
どれもそんなたいしたことではありませんが、ライブラリに対する理解が一歩深まったのは確かだと思います。 これからのC++ライフがほんのちょっとだけ楽になりそうです。
2007年09月01日
組込みI/Oインタフェース基礎講座
組込みI/Oインタフェース基礎講座
という本を読みました。
パラレルI/OやシリアルI/Oなど、各種I/Oの基本的な仕組みについての本ですが、 前に読んだWrite Great Codeよりも 深い所まで踏み込んでいます。ちゃんと波形まで出てきます。
本書のパラレルI/OとシリアルI/Oの解説は分かりやすく、読み応えがありました。
パラレルI/Oの解説では、パソコンのプリンタポートが例に出てきます。
パソコンがプリンタポートを通してどのようにどのように外部機器とハンドシェークを行い、どのようにデータを送受信するのか、ソフトウェア屋さんでも分かるくらい詳しく書いてあります。
シリアルI/Oの方は、RS-232C、SPI、I2Cの解説がありました。I2Cのバス調停の仕組みあたりは理解できると結構面白いです。
パラレルI/Oも、シリアルI/Oも、データを取りこぼさす送受信するためにさまざまな工夫が凝らしてあり、興味深かったです。
ケーブル繋いでデータを送るというのは簡単そうに思えるかもしれませんが、結構大変なんですね・・・。
本書は、バスについての知識を深めたい組込みソフトウェア屋さんにお薦めです。
最近のパソコンではPCI Expressなどの超高速バスが使われていて、本書の内容では全然追いついてないと思いますが、
組込みの世界ではまだまだ色々な低速バスが使われているので、本書の内容でも知識が深まります。